
The biggest challenge in document processing and understanding using NLP is the shortage of training data and deep learning models to interpret the data as well as humans do. This is because document processing and understanding is a diversified field with many distinct tasks and is most task-specific.
To help close this gap in data extraction and understanding, Tech Vedika has developed an NLP XEngine for purpose-based deep understanding models that could be used in a wide variety of tasks. The pre-trained model can then be fine-tuned on any document for understanding tasks like document classification, clustering, correction, etc.
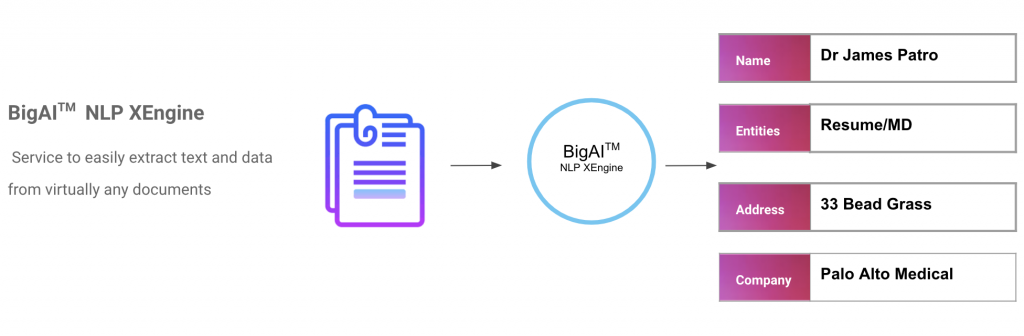 NLP XEngine builds upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. Our methods use deeply bidirectional, supervised language representation on any industry-specific text dataset.
Deep Learning Algorithms
As opposed to commercial directional models, which read the text input sequentially (left-to-right or right-to-left), our NLP engine transformer encoder reads the entire sequence of words at once. Hence, it is considered bidirectional, though it would be more accurate to say that it’s non-directional. This characteristic allows the model to learn the context of a word based on its surroundings (left and right of the word). Our algorithms are the state-of-the-art machine learning algorithms that enable document classification, clustering, understanding, etc.
NLP XEngine builds upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. Our methods use deeply bidirectional, supervised language representation on any industry-specific text dataset.
Deep Learning Algorithms
As opposed to commercial directional models, which read the text input sequentially (left-to-right or right-to-left), our NLP engine transformer encoder reads the entire sequence of words at once. Hence, it is considered bidirectional, though it would be more accurate to say that it’s non-directional. This characteristic allows the model to learn the context of a word based on its surroundings (left and right of the word). Our algorithms are the state-of-the-art machine learning algorithms that enable document classification, clustering, understanding, etc.

NLP XEngine builds upon recent work in pre-training contextual representations — including Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, and ULMFit. Our methods use deeply bidirectional, supervised language representation on any industry-specific text dataset.
Deep Learning Algorithms
As opposed to commercial directional models, which read the text input sequentially (left-to-right or right-to-left), our NLP engine transformer encoder reads the entire sequence of words at once. Hence, it is considered bidirectional, though it would be more accurate to say that it’s non-directional. This characteristic allows the model to learn the context of a word based on its surroundings (left and right of the word). Our algorithms are the state-of-the-art machine learning algorithms that enable document classification, clustering, understanding, etc.